بطور معمول، برنامههای مدرن از موتورهای مختلف پایگاه داده برای نیازهای سرویس خود استفاده میکنند؛ در Grab ، اینها شامل MySQL ، Aurora و DynamoDB است. اخیراً تیم Caspian نیاز روز افزونی برای مصرف دادههای زمان واقعی در بسیاری از تیمهای سرویس مشاهده کرده است. این تغییرات در زمان واقعی در رکوردهای پایگاه داده به پشتیبانی از تصمیمات تجاری آنلاین و آفلاین برای صدها تیم کمک میکند.
بدلیل این موضوع، ما وقت خود را به هماهنگسازی دادهها از MySQL ، Aurora و Dynamodb تا صف پیام، به عنوان مثال Kafka سپردهایم. در این بلاگ، ما در مورد این که چگونه مصرف دادههای زمان واقعی کمک کرده است، میگوییم.
در چند سال اخیر، تیمهای سرویس باید تمام دادههای معاملاتی را دو بار بنویسند: یک بار در Kafka و یک بار در پایگاه داده. این به حل چالشهای ارتباط بین سرویسها و به دست آوردن لاگهای ردیابی کمک کرده است. با این حال، در صورت عدم موفقیت تراکنشها، اصالت داده مشکلی مهم میشود. علاوه بر این، نگهداری طرح دادههای مورد نوشتن در Kafka یک کار دشوار برای توسعه دهندگان است.
با جذب زمانبندی، تکامل طرح بهتر و قطعیت داده تضمین شده و تیمهای سرویس دیگر نیازی به دو بار نوشتن داده ندارند.
شاید شما در حال تعجب باشید که چرا ما یک تراکنش تکی که بانک اطلاعات سرویسها و Kafka را دربرگیرد برای ارائه داده یکنواخت استفاده نمیکنیم؟ این کار نمیتواند انجام شود زیرا Kafka از ورود به تراکنشهای توزیع شده پشتیبانی نمیکند. در برخی موارد، ممکن است داده جدیدی در پایگاه دادههای سرویسها ثبت شود، اما پیام مربوطه به تاپیکهای Kafka ارسال نشود.
به جای ثبت نام یا اصلاح طرح نگاشتی در نویسنده Golang به Kafka قبل از دست بردن از دست بردن طرح، تیمهای سرویس به طور کلی تمایل دارند از چنین تکالیف نگهداری طرحی اجتناب کنند. در چنین مواردی، میتوان از جذب زمان واقعی استفاده کرد که در آن تبادل داده بین پایگاههای داده متعدد یا تکثیر بین منبع و نمونههای پشتیبانی مورد نیاز است.
هنگام بررسی چالشهای اصلی در مورد جذب داده زمان واقعی، متوجه شدیم که بسیاری از نیازهای کاربر پتانسیلی وجود دارد که باید شامل شود. برای ساخت یک راه حل استاندارد، چندین نکته اولیه که ما احساس کردیم اولویت بالایی دارند، شناسایی کردیم:
- به عنوان مثال گرفتن حق دسترسی به دادههای معاملاتی در زمان واقعی برای اتخاذ تصمیمات تجاری به مقیاس.ثبت لاگ از هر پایگاه داده داده شده.
برای اعطای قدرت برنامههای Grabbers با دادههای زمان واقعی برای اتخاذ تصمیمات تجاری خود، ما تصمیم گرفتیم رویکردی قابل مقیاس را که با مجموعهای از محصولات داخلی تسهیل میشود، انتخاب کنیم و یک راه حل برای جذب دادههای زمان واقعی طراحی کنیم.
ساختگی معماری
راه حل برای جذب دادههای زمان واقعی چندین جزء کلیدی دارد:
- ذخیره دادههای استریمتولید کننده رویدادصف پیامپردازنده استریم
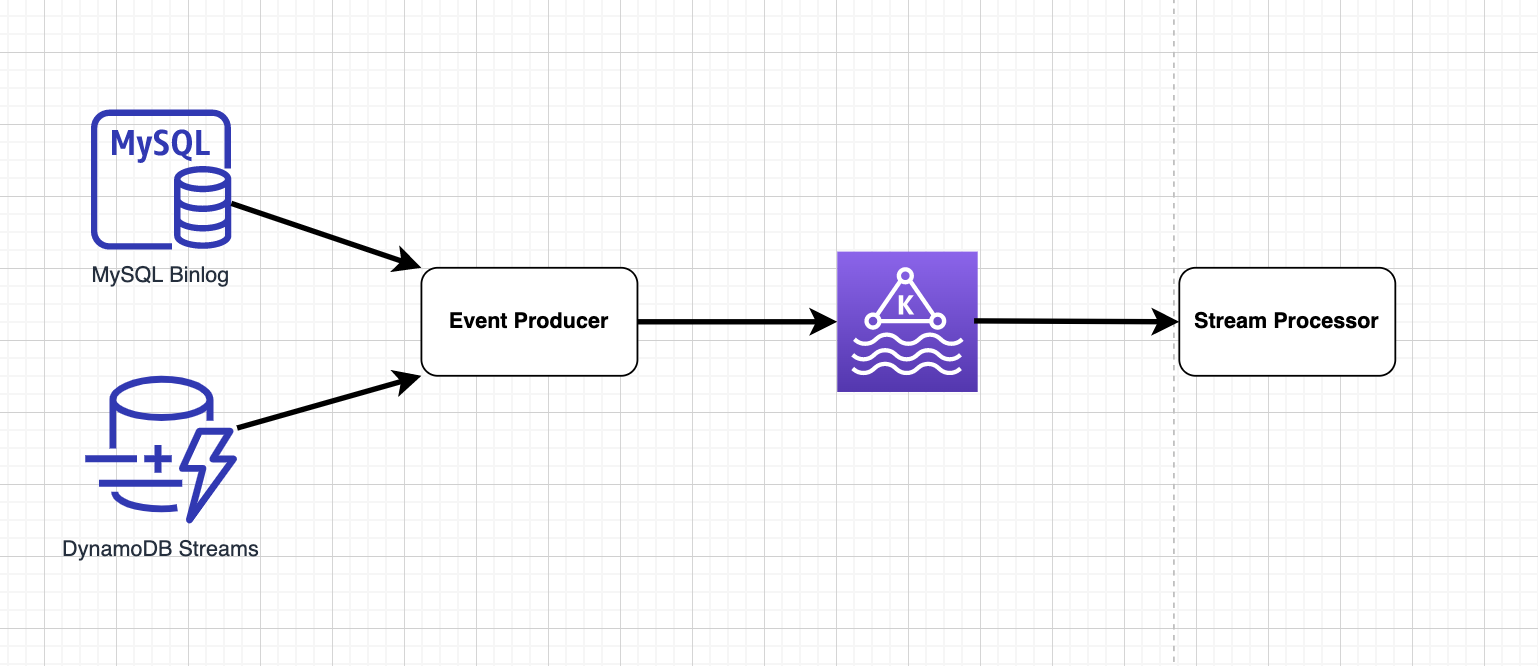
ذخیره استریم
ذخیره استریم عمل میکند که تراکنشهای داده را به ترتیب با تضمین یک بار دقیق ذخیره میکند. با این حال، سطح ترتیب در ذخیره استریم با توجه به پایگاه دادههای مختلف متفاوت است.
برای MySQL یا Aurora، دادههای تراکنش در فایلهای binlog به ترتیب و چرخشی ذخیره میشوند، بدین ترتیب ترتیب کلی را تضمین میکنند. داده با ترتیب کلی تضمین میکند که همه رکوردهای MySQL مرتب شده و واقعیت زندگی واقعی را نشان میدهند. به عنوان مثال، هنگامی که لاگهای تراکنشی بازیشوند یا توسط مصرفکنندگان پایینجریان مصرف شوند، سفارش غذای مشتری A ساعت 12:01 عصر پیش از سفارش مشتری B ساعت 12:01:45 عصر همیشه ظاهر میشود.
با این حال، این موضوع برای ذخیره استریم DynamoDB در حقیقت درست نیست زیرا استریمهای DynamoDB به صورت بخشی شده هستند. گزارشهای حق تملکی از یک رکورد داده میدهد که آنها به ترتیب به همان بخش در همان بخش میروند و ترتیب بخشبندیشده است. بنابراین در هنگام پخش دوباره اتفاق میافتد که سفارش مشتری B ممکن است قبل از سفارش مشتری A ظاهر شود.
علاوه بر این، برای هر دو فرمت binlog و رکوردهای استریم DynamoDB ، چندین فرمت برای انتخاب وجود دارد. در نهایت ما برای فرمتهای binlogROW و NEW_AND_OLD_IMAGESرا تنظیم میکنیم. این نشان میدهد ناهمواره قبل و بعد از اصلاح هر رکورد جدول داده شده اطلاعات تفصیلی را نشان میدهد. فیلدهای اصلی binlog و DynamoDB stream در شکلهای 2 و 3 به ترتیب جدولبندی شده اند.
تولید کننده رویداد
تولید کننده رویدادها پیامهای binlog یا رکوردهای استریم را وارد صف پیام میکنند. ما چندین فناوری را برای مختلف موتورهای پایگاه داده بررسی کردیم.
برای MySQL یا Aurora، سه راهحل مورد ارزیابی قرار گرفته است: Debezium ، Maxwell و Canal. ما انتخاب کردیم تا Debezium را به عنوان یکی از آنها به حاشیه بگذاریم زیرا با چارچوب Kafka Connect یکپارچه شده است. علاوه بر این، ما مشاهده کردیم که پتانسیل گسترش را در میان سایر سیستمهای خارجی هنگام انتقال مجموعههای بزرگی از داده به درون خوشه Kafka دارد.
یکی از مثالهای شبه منبع باز مشابه این است که سعی میکند یک اتصال سفارشی DynamoDB را گسترش دهد که چارچوب Kafka Connect (KC) را گسترش دهد. این تابع حساب میکند که وسیله مدیریت چکپوینت را از طریق جدول اضافی DynamoDB انجام دهد و میتواند به خوبی در KC استقرار یابد.
با این حال، کانکتور DynamoDB نمیتواند از طریق طبیعت اساسی استریمهای DynamoDB استفاده کند: بخشبندی پویا و مقیاسپذیری خودکار بر اساس ترافیک. به جای آن، تنها یک وظیفه نخ تکی را برای پردازش تمام شارههای جدول DynamoDB دارد. نتیجه این است که سرویسهای پایینجریان در مواقعی که ترافیک نوشتن بالا میتابد، بیش از همه از تاخیر داده رنج میبرند.
با توجه به این موضوع، تابع Lambda به عنوان منبع تولید رویداد مناسبترین کاندیدایی است. نه تنها همزمانی توابع لامبدا براساس ترافیک واقعی مقیاس میکند، بلکه فرکانس تریگر قابل تنظیم است و شما میتوانید بر اساس تصمیم خود تعیین کنید.
کافکا
این مخزن داده توزیع شده است که برای جذب و پردازش داده به صورت زمان واقعی بهینه شده است. به دلیل مقیاسپذیری بالا، مقاومت در برابر خطا و پردازش همزمان، به طور گسترده ای پذیرفته شده است. پیامها در Kafka تجری شده و در Protobuf رمزگذاری میشوند.
پردازشگر استریم
پردازنده استریم پیامها را در Kafka مصرف کرده و هر دقیقه به S3 بنویسید. چندین گزینه آماده در بازار وجود دارد؛ Spark و Flink بیشترین گزینههای رایج هستند. در Grab ، ما یک کتابخانه Golang را برای مقابله با ترافیک استفاده میکنیم.
کاربردها
اکنون که راجع به اینکه چگونه جذب دادههای زمان واقعی در Grab انجام میشود، صحبت کردیم، بیایید به برخی از موقعیتهایی که میتوانند از جذب دادههای زمان واقعی بهرهبرداری کنند، نگاه کنیم.
1. خطوط لوله داده
ما در Grab هزاران خط لوله را در هر ساعت اجرا میکنیم. برخی جداول رشد قابل توجهی داشته و بار کاری را فراتر از آنچه که یک پرس و جوی SQL مبتنی بر کوئری میتواند کنترل کند، ایجاد میکنند. خط لوله داده ساعتانه باعث ایجاد افزایش خواندن در پایگاه داده تولیدی که میان خدمات مختلف به اشتراک گذاشته میشود و منابع CPU و حافظه را خالی میکند. این باعث کاهش عملکرد خدمات دیگر و حتی ممکن است آنها را از خواندن محدود کند. با جذب زمان واقعی، پرس و جوی خطوط لوله داده به صورت تدریجی و در یک بازه زمانی پخش میشود.
سناریوی دیگری که به جذب زمان واقعی میپردازیم، زمانی است که بر روی جدول شاخص از دست رفته تشخیص داده میشود. برای سرعت بخشیدن به پرس و جو، جذب پرس و جوی مبتنی بر SQL نیاز به ایجاد شاخص بر روی ستونهای مانند created_at ، updated_at و id دارد. بدون شاخصگذاری، جذب پرس و جو مبتنی بر SQL میتواند منجر به مصرف بالای CPU و حافظه یا حتی شکست شود.
اگرچه اضافه کردن شاخص برای این ستونها میتواند این مشکل را حل کند، اما هزینهای به همراه میآورد، به عبارت دیگر کپی از ستون شاخص گرفته میشود و کلید اصلی در دیسک ایجاد میشود و شاخص در حافظه نگه داشته میشود. ایجاد و نگهداری یک شاخص در یک جدول بزرگ هزینهبرتر از جداول کوچکتر است. با توجه به ملاحظات عملکرد، توصیه نمیشود شاخصها را به یک جدول بزرگ موجود اضافه کنید.
در عوض، جذب زمان واقعی جذب پرس و جوی مبتنی بر SQL را سایه میاندازد. ما میتوانیم یک کانکتور جدید و یک آرشیوکننده (کتابخانه Golang Coban تیم) و یک کار تراکم را برای ایجاد ارتباط از binlog به جدول مقصد در lake داده بیرون کنیم.
2. رساندن تصمیمات تجاری
یکی از موارد استفاده کلیدی از جذب داده زمان واقعی برای اتخاذ تصمیمات تجاری به مقیاس بدون حتی لمس خدمات منبع است. الگوی Saga در دنیای میکروسرویس رایج است. هر سرویس دارای پایگاه داده خود است و یک تراکنش بانکی کلی را به چندین تراکنش پایگاه داده تقسیم میکند. ارتباط بین این سرویسها از طریق صف پیام برقرار میشود یعنی Kafka.
در یک بلاگ تکنولوژیای قبلی که توسط تیم جستجوی مجله زیبایی و درمانی آذروت منتشر شده است، در مورد این صحبت کردیم که چگونه جذب زمان واقعی با Debezium قابلیتها و قابلیتهای جستجو را بهینه و افزایش میدهد. هر جدول MySQL به یک موضوع Kafka نگاشت میشود و یک یا چندین موضوع ساختار جستجو را در Elasticsearch ایجاد میکنند.
با این رویکرد جدید، هیچ داده ای از دست نمیرود، به عبارت دیگر تغییرات از طریق ابزار خط فرمان MySQL یا ابزارهای مدیریت دیگر پایگاه دادهها قابل ضبط است. تکامل طرح نیز به طور طبیعی پشتیبانی میشود؛ طرح جدید که در یک جدول MySQL تعریف شده است، به ارث برده میشود و در Kafka ذخیره میشود. برای هماهنگی طرح با آنچه در MySQL وجود دارد، نیازی به تغییر کد تولید کننده نیست. علاوه بر این، خواندن پایگاه داده با توجه به تلاشهای پلتفرم هماهنگسازی داده 90 درصد کاهش یافته است.
تیم GrabFood بیشترین مزیتهای مشابه در حوزه DynamoDB را نشان میدهد. تنها تفاوتهای آن نسبت به MySQL این است که فرکانس تابع لامبدا قابل تنظیم است و پاراللیسم بر اساس ترافیک اتوماتیک مقیاس میشود. با توجه به مقیاسپذیری خودکار، منظور از بالا و پایین تابع لامبدا این است که مواردی که ناگهان ترافیک بالا را تجربه میکند، تابعهای لامبدا بیشتری برای خدمت رسانی خودکار ایجاد میکند، یا با کاهش ترافیک منسوخ میشود.
3. تکثیر پایگاه داده
یکی از موارد استفاده که در ابتدا در نظر نگرفته بودیم، تکثیر دادههای فزاینده برای بازیابی بحرانی است. در Grab، ما چشماندازهای DynamoDB را برای جداول tier 0 و مهم فعال میکنیم. هر عملیات درج ، حذف ، اصلاح به طور ناگهانی به جلو میروند.